本文同步发布到知乎
背景
最近因为项目原因,在项目中使用 Emscripten 将 C++ 代码编译到 WASM 以便在浏览器执行。借助这个过程我也学习了 WASM 上代码执行的方法。借助这个机会,用这篇文章介绍 C++ 是如何借助 WASM 字节码是执行的。
名词解释
- WASM: WebAssembly,这个不多介绍了。
- WAT: 用来表示 WASM 字节码的一种文本格式。
- Emscripten: 用于把 C++ 代码编译成 WASM 的编译器,基于 LLVM。
WebAssembly 字节码执行
这一段主要解释 WASM 字节码执行的过程。如果了解可以跳过。
要想知道 WebAssembly 怎么执行。我们就要知道 WASM 字节码如何表示,有哪些类型和指令。编译完成可以执行的 WASM 程序是一个紧凑的二进制程序。 但是我们仍然可以用一种语言来表示 WASM 程序,我们称之为 WAT - WebAssembly Text Format。 WAT 就像汇编之于机器码一样。我们虽然不能直接阅读 WASM 字节码,但是我们可以通过阅读 WAT 来了解程序的执行过程。
基本类型
和 Js 不同,WASM 是强类型的,WASM 程序里面运行的“值”有四个基本类型。其他的类型都由这四个基本类型组合而成。
- i32
- i64
- f32
- f64
从字面意思我们可以知道分别代表 32 位和 64 位整数和浮点数。
指令
要了解 WASM 的指令。就要了解 WASM 的“机器模型”。和我们现在运行的物理机不同,WASM 的运行环境是虚拟机,而且是一个栈式的虚拟机。栈式的虚拟机是和寄存器机器区分开的一个概念。下图展示了一个栈式机器执行的过程。前两句分别表示往栈上 push 两个值,最后一句执行加法操作,取栈顶两个值相加,然后结果再推回栈上。
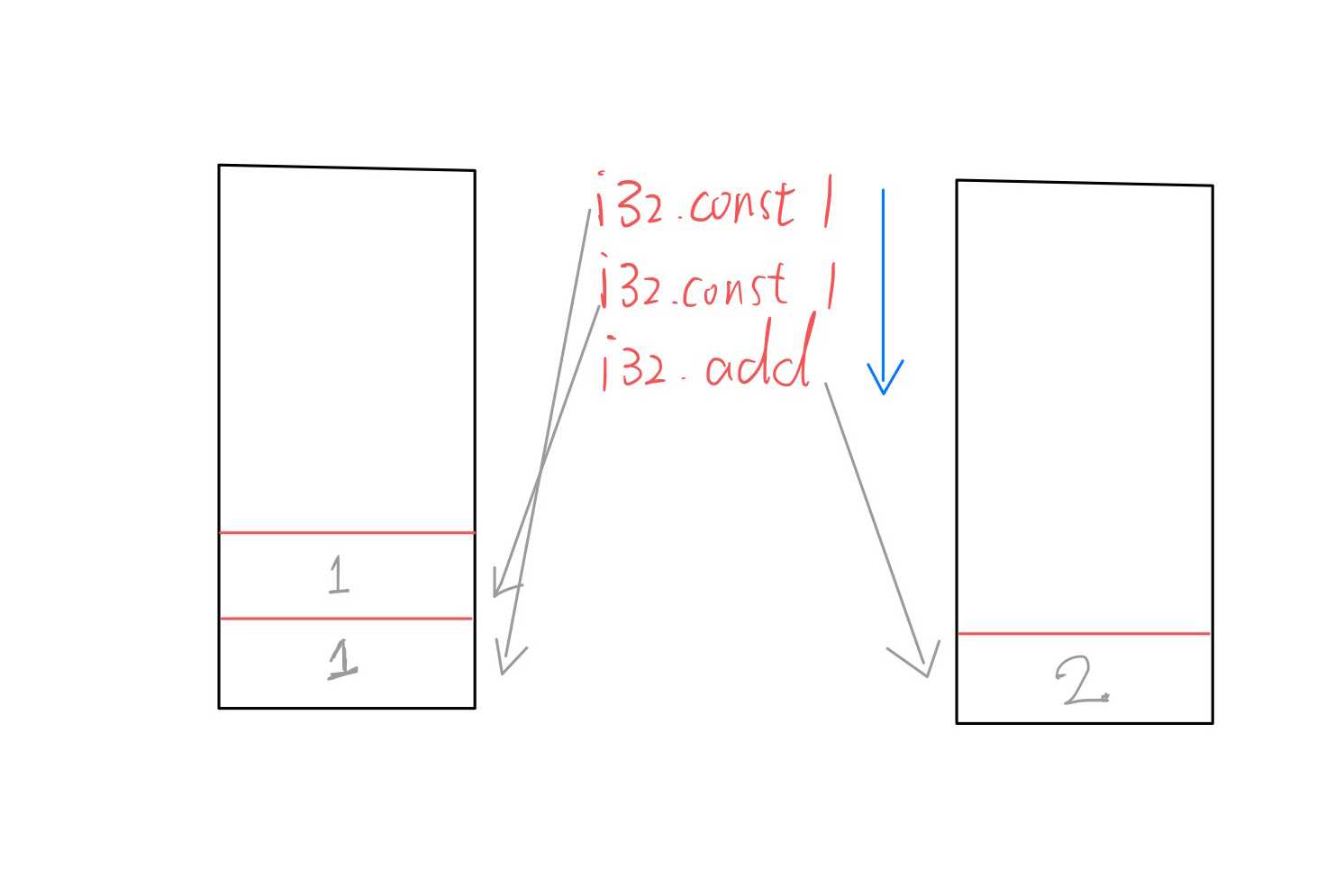
图为栈式虚拟机上 32 位整数的加法操作
本地变量
对于 WASM 程序里面的每个“函数”都有“本地变量”这个概念,在函数的头部定义。
每个本地变量都有一个“编号”,而通过相应的指令,我们可以读取,写入这个变量的值,这两个指令分别是 local_set 和 local_get。
再配合上类型,比如 i32.local_get 0 就把 0 号本地变量读取出来,然后 push 到栈上。
内存空间
WASM 的内存空间是线性,这个倒是跟我们的物理机很像。 Emscripten 编译出来的产物里面,对于内存空间,同样分了“栈”空间和“堆”空间。这里很容易混淆的一点是。 这里的“栈”空间并不是上面说的“栈”式虚拟机的那个栈,而是内存空间上的一个概念。 C 语言的函数里面的本地变量,其实也存在于这个内存栈上(如果没有被编译器优化的话)。
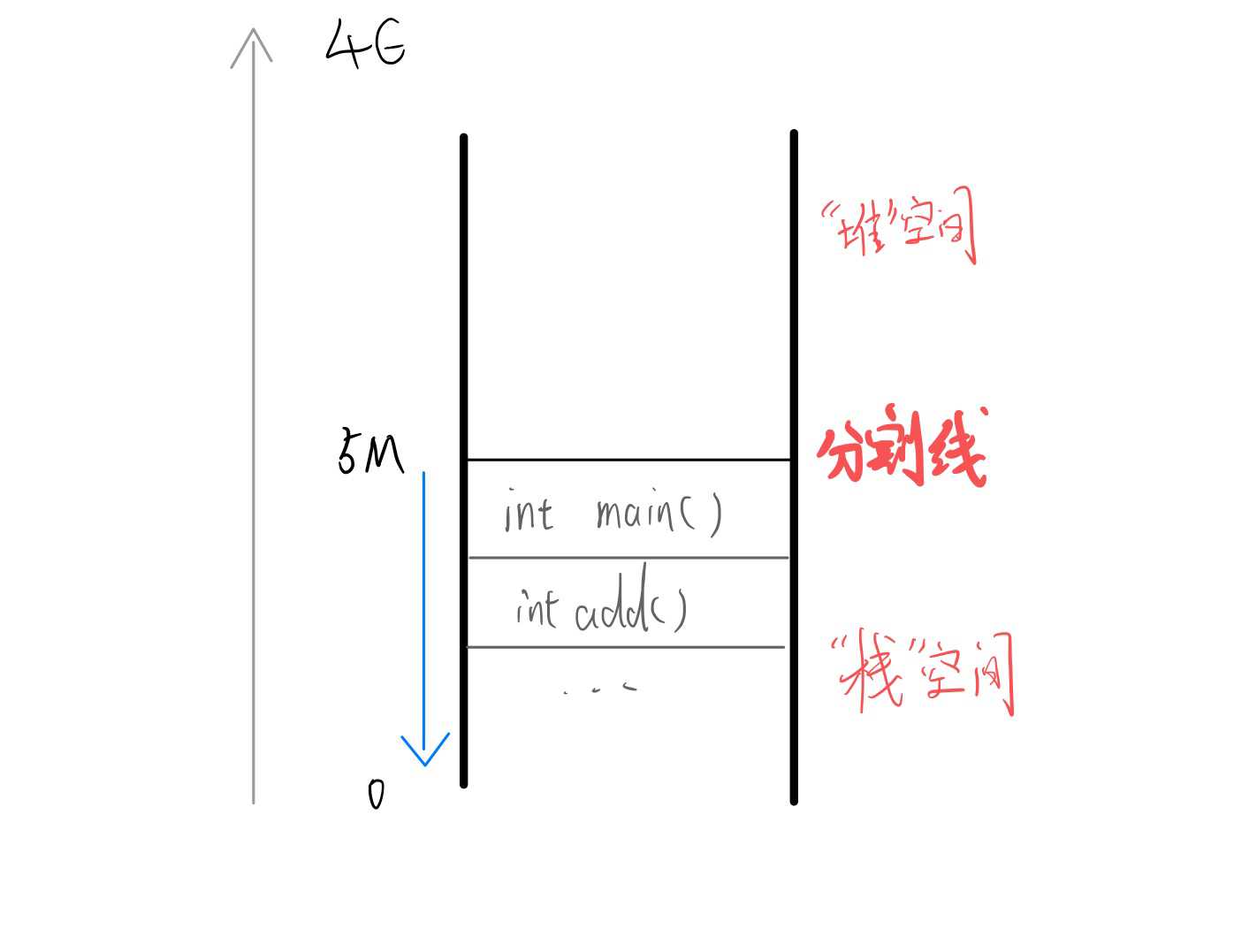
上图展现了一个 Emscripten 编译出来的 C 语言程序的内存空间。Emscripten 默认分配的栈空间是 5M。而栈空间是从内存的高位往低位增长的,这里可以抛出一个问题,这样设计会带来什么好处呢?。而“堆“空间就很容易理解了,这里不展开。
反编译
懂了大概这些概念之后,我们就可以动手了。如果还不了解的话,实际用到的时候再回来看看,会更容易理解。
实验代码
int add(int a, int b) {
return a + b;
}工具
反编译的工具这里用的是 WABT: WABT
命令
wasm2wat test_wasm.wasm > test.txt得到的这个 test.txt 就是反编译后 WAT 格式的代码了。然后你应该能看到类似这样的代码:
(module
(type (;0;) (func (result i32)))
(type (;1;) (func (param i32)))
(type (;2;) (func (param i32) (result i32)))
(type (;3;) (func))
(type (;4;) (func (param i32 i32) (result i32)))
(type (;5;) (func (param i32 i32 i32) (result i32)))
(type (;6;) (func (param i32 i64 i32) (result i64)))
(func $__wasm_call_ctors (type 3)
call $emscripten_stack_init)
(func $add_int__int_ (type 4) (param i32 i32) (result i32)这里你可能看不懂,但是也能大概猜出来里面的含义。以 type 开头的意思为分别定义了这些类型。以 func 开头则是代表定义了这些函数。下面我很很自然就看到 add_int 这个函数,这里摘取一部分代码:
(func $add_int__int_ (type 4) (param i32 i32) (result i32)
(local i32 i32 i32 i32 i32 i32)
global.get $__stack_pointer
local.set 2
i32.const 16
local.set 3
local.get 2
local.get 3看到这段代码我们要给这些变量编个号码,从 param 开始从 0 开始数,result 不算,遇到一个变量就加一,直到分配完所有变量。

而聪明的你一定就会发现,下面代码里面所谓的 local.get 和 local.set 后面的数字所代表的变量就是这几个变量。
接下来看看 debug 模式下如何读取和存储 a 变量。
global.get $__stack_pointer
local.set 2 // 2 <- stack_pointer ; 把栈指针放到 2 号槽
i32.const 16
local.set 3 // 3 <- 16 ; 把数字 16 放到 3 号槽
local.get 2
local.get 3
i32.sub // 2 号和 3 号相减,推到栈上
local.set 4 // 4 <- stack_pointer - 16 ; 把 stack - 16 放到 4 号槽,这个代表这个函数的基地址,函数内变量都通过基地址 + 偏移来进行访问。这里表示这个函数占用 16 bytes 的栈大小
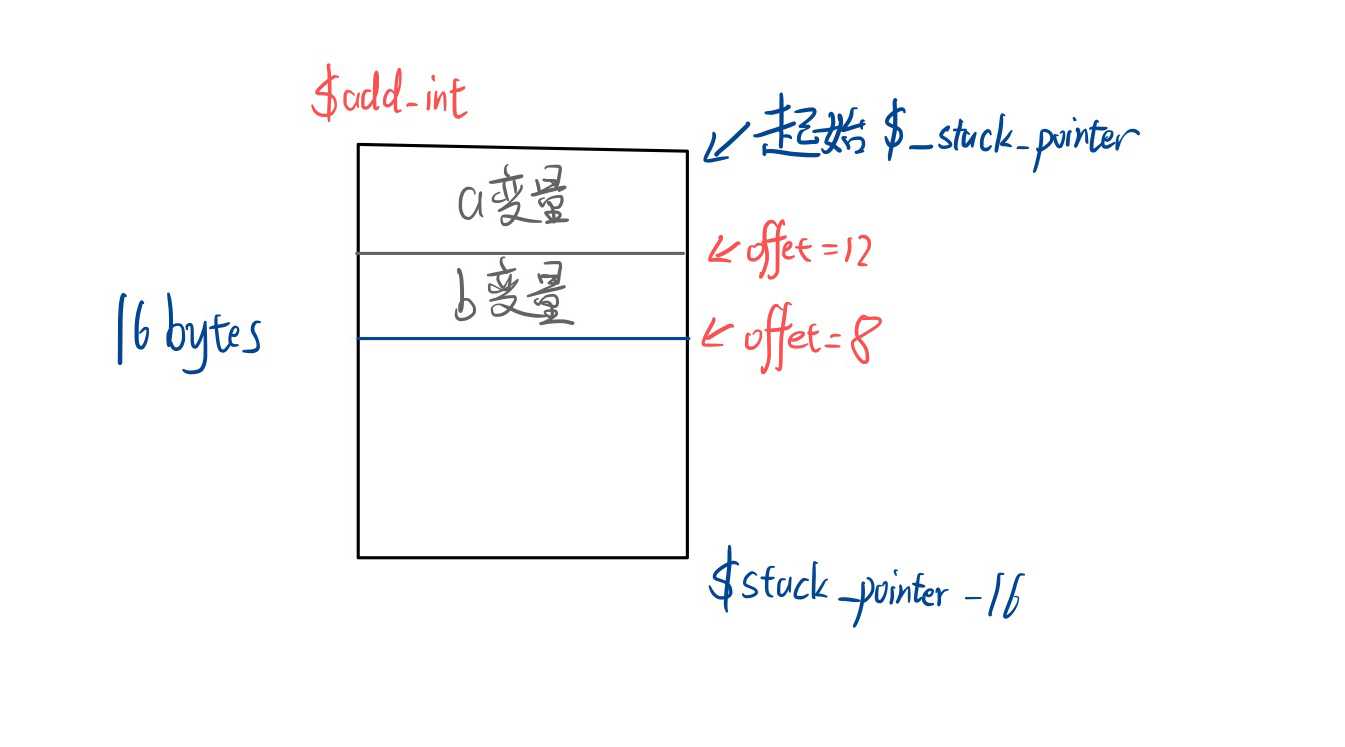
图为 add 函数的内存布局
Release 模式的优化
Debug 模式下,生成的代码会比较啰嗦,先把参数 a, b 放到内存的这两个位置。然后再重新读出来,然后进行相加。然后再返回。这个时候或许我们会想,其实这里是不是没有必要写到内存,直接相加就可以了。就像我们 native 程序,有些变量直接在寄存器就能相加。所以 Release 模式下是没有写到内存的。
(func (;2;) (type 0) (param i32 i32) (result i32)
local.get 0
local.get 1
i32.add)以上就是 Release 下生成的代码,不涉及内存操作。
总结
以上讲述了 C++ 如何在借助 WASM 在浏览器里执行。相比机器码,WASM 读起来要易懂得多,我们也可可以借此机会多了解编译器如何理解和编译我们的代码,达到举一反三的效果。