背景
平时大家在开发 Js 项目的时候,可能已经离不开 webpack 等打包工具了。而 webpack 打包速度大概就是“能用“的水平。大概去年开始,我就开始在构想,如果能写一个极速的打包工具,功能未必需要很强,可能对小项目非常有用。去年我用 C++ 写完 parser 之后,便没什么动力写下去了。但是最近发现有这个想法的不止我一个,Figma 的 CTO 业余之际写了一个打包器 https://github.com/evanw/esbuild,可以说完完全全实现了我想象中的需求,不过他是用 Go 语言实现的。我看到这个项目时心里一想,这不是我去年就想做的事吗,这 push 我赶紧把打包压缩部分完成。
代码
Github 地址:https://github.com/vincentdchan/jetpack.js
优化思路
并行 Parsing
毫无疑问,每一个 js 文件的 parsing 可以在不同线程完成,这就需要支持并行的语言。由于 parsing 的结果是 AST,所以需要可以共享内存的语言(排除通过 messeage parsing 实现多线程的语言)。满足以上两个要求的语言不多。 Evan 选择了 Go,我选择了 C++。
减少遍历次数
要想速度快,就要减少 AST 的遍历次数。最好就是只遍历一次来生成代码,在 Parsing 构建 AST 的时候就收集足够的信息。但是这也意味着只能做比较浅层次的优化,不能做深层次的压缩(死代码消除,tree shaking 都做不了)。
架构
由上述思路我总结出了以下打包的架构:
- 并行 parse 文件
- 作用域提升、生成框架代码、重命名变量
- 并行生成代码
- 合并输出文件
流程图如下:

打包压缩原理
本章节主要讲如何“最简单“地压缩 Js 代码。本章节假设读者对编译原理有一定了解,知道什么是 AST。如果不懂请直接跳到下文「性能」章节。
字面量替换
字面替换最简单。规则有一下几个:
- undefined 替换为
void 0 - true 替换为
!0, false 替换为!1
⚠️ 注意:在 ES 中,undefined 是标识符(Identifier),而不是关键字,也就是说你可以定义一个叫 undefined 的变量,所以这个时候不能简单地替换为 void 0
常量折叠
计算简单的运算:
var two = 1 + 1;
var foobar = 'foo' + 'bar';转换成
var two = 2;
var foobar = 'foobar';⚠️ 注意:这里要注意实现的平台和 js 的差异,比如在 C++ 里面大整数相加可能会溢出,而在 Js 会自动转换成 bigint. 加法问题就如此,其他运算符问题更多。如果要完整实现常量折叠,可能要部分实现 js 引擎。
变量别名
别名就是要给变量重新赋予比较短的变量名。从字母一直排上去,abcd,一个字母用完了用两个字母。实现起来也很简单,用一个计数器,一直加上去就可。最后每个变量分配一个数字,把这个数字映射到相应的英文字母上,有点像 36 进制转换成字母的面试题。不过这里有一点值得注意的是,变量名第一个字母不能是数字,第二个字母开始可以是数字,要考虑到这一点,才能尽可能“压榨”变量名。
为了尽可能地“压榨”变量名,同一级的作用域里面的变量名是可以使用相同的变量名。到下一级的时候,对子作用域进行合并。
举个例子:
function Mother() {
var e = 'capture'; // d 不能使用跟子作用域同样的变量名,不然子作用域无法捕获这个变量
function A(a, b, c, d) {
console.log(e);
}
function B(a, b, c) { // B 跟 A 函数同级,分配同样的变量名
// ...
}
}上述例子中,A 和 B 都没有子作用域了,变量名从 0 开始分配。到给 Mother 下 e 分配变量名时,找到子作用域最大的计数器。分配最多的子作用域 A 分配了 4 个,所以 B 计数器从 5 开始分配,所以给 e 分配了5,所以 e 就得到了这个名字。
所以变量别名就是从 AST 的叶子开始向上构造,一直分配到根结点把所有作用域都分配完为止。
小技巧
这里 esbuild 采用了比较聪明的技巧。它统计了所有变量的引用次数,然后进行排序,引用次数最多的变量分配到的名字就是尽量短的,这样也可以减少编译出来 js 的体积。我在写 jetpack 打包的时候,也借鉴了这种做法。
模块合并
模块合并的办法有很多。webpack 采用的是用 function 把每个函数包起来,放到了一个长长的数组里面,然后实现了自己的 require,esbuild 也采用了类似的方法。
Rollup.js 实现的方法则是作用域提升(Scope hoisting),把模块都放到根作用域。这里我采用的方法也是作用域提升。
假设有 a.js 文件:
export function A() {
console.log('a');
}然后有 main.js 文件:
import { A as ExternalA } from './a';
function A() {
console.log('local A');
}
export function main() {
A() + ExternalA();
}使用 jetpack 打包完的结果:
// a.js
function A() {
console.log('a');
}
// main.js
function A_0() {
console.log('local A');
}
function main() {
A_0() + A();
}
export { main };难点在于作用域合并。实际上在 ES modules 里面不同 modules 之间引用是一个图结构。
C++ 的优化
除了策略上的优化,C++ 还提供了诸多基础数据结构/内存方面的优化。
shared_ptr
AST 的结点全部使用 shared_ptr,有人可能认为这是一个很大的开销。但是早期的时候我实现过一个裸指针版本(不释放内存),并没有测出有明显差距。
使用 shared_ptr 很重要一个原因是,一个子树可能被其他类拥有(打包模块,Scope,ES Module 管理器)。这个时候如果用 unique_ptr 的话就会 gg。只能说 GC 大法好。
对于 C++ 这种没有 GC 的语言有一个毛病就是:析构 AST 非常耗时。AST 够大的话能耗上十几 ms(这个时间跟 gc 比有何优势?),所以因此我也能想出了一个办法:不释放内存……。
最后说一句:GC 大法好。
robin hood hashing
由于打包器中大量使用哈希表,所以提高哈希表速度尤其重要,这里我使用了 robin hood hashing
参见:https://martin.ankerl.com/2019/04/01/hashmap-benchmarks-01-overview/
在 hash 方面我有一个设想,就是像 Lua 一样,对于短字符,在字符串创建的时候把 hash 记下来,这样在多次使用哈希表的时候可以节省 hash 的时间(但是要求字符串是 immutable 的)。为此我专门写了个 String 类,最后的结果是总体速度慢了 2-3x,测出来是 immutable 字符串拼接耗时太多,最后放弃了这个方案。
jemalloc
Parsing 过程中需要大量分配 node,大家都知道很明显 C++ 的 new 并不够快。经过测试在 macOS 下使用 jemalloc 会让 parsing 速度提升 1 倍。使用系统 malloc 会导致 parsing 速度比 Go 慢 1x 左右,慢在 new。
当然了,内存池我也试过的,测出来速度基本和 jemalloc 一样,所以就直接用 jemalloc 了。
性能
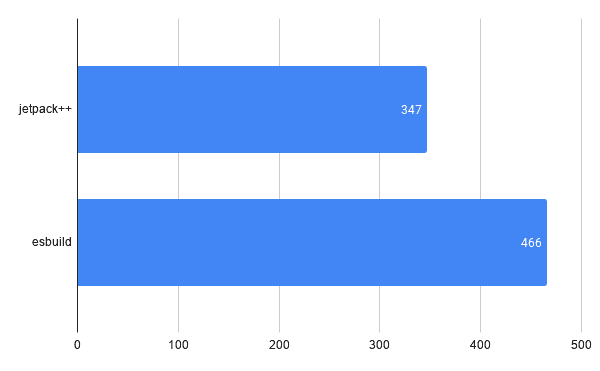
总结
写编译器需要快速大量产生 node 结点,大量树和图的结构,这一方面的运算 C++ 并没有什么优势可言。
不得不承认,使用 C++ 你要思考很多东西,做很多很多额外的工作,才能获得比 Go 还快的速度(什么都不想做出来只会比 Go 还慢)。另一方面使用 C++ 会让你额外考虑很多和业务无关的东西,大大降低开发速度,而对于打包器这个场景 C++ 在这一块本身不能提供很大优势。